V súčasnej dobe viac ako kedykoľvek predtým je potrebné prezentovať zozbierané údaje vo forme rôznych prehľadov. Dôležitým faktorom okrem validity dát je aj čas potrebný na vytvorenie požadovaného prehľadu. Niekoľko príkladov:
- prehľad o pracovníkoch podniku a ich pracovných výkonoch za určité obdobie
- výkaz o zápočtoch a skúškach
- zoznam podaných daňových priznaní členený podľa typu daň. priznania, regiónu atď..
- zoznam neplatičov podľa zadaných kritérií
Požiadavka na rýchlosť je opodstatnená, lebo ak napríklad vedenie podniku dostane prehľad výkonov svojich zamestnancov za uplynulý mesiac neskoro (napr. z mesačným oneskorením), nemôže flexibilne meniť zaradenie a pracovnú náplň zamestnancov.
Okrem faktora času treba zdôraniť aj ďalšie črty ako napríklad spôsob, metodika tvorby reportu. Kladie sa veľký dôraz na jednoduchosť a zrozumiteľnosť riešenia, intuitívne ovládanie použitých nástrojov, správne rozdelenie rolí v procese tvorby reportu. Otvorenosť a rozšíriteľnosť nástroja, možnosť rozšírenia tretími stranami, podpora rôznych výstupných formátov a prehliadačov reportov (napr:web prehliadač), export/import, zapojenie v rámci ďalších systémov podniku, či organizácie. Otvorenosť, v zmysle tvorby riešenia na otvorených technológiách a štandardoch napr:XML. V neposlednom rade aj kvalitná dokumentácia riešenia i výsledných reportov, ako aj zriaďovacie a prevádzkové náklady, jednoduchosť inštalácie a údržby systému.
Pre účely tejto práce reportingom nazývame každý proces, ktorého výsledkom je prezentácia nejakej množiny dát vo forme prehľadu. Výstupnou zostavou alebo reportom nazývame výsledok tohto procesu. Pri tvorbe reportom najčastejším dátovým zdrojom sú dáta uložené v relačných databázach ale už ani to nie je pravidlom a ako poukážeme neskôr sú opodstatnené požiadavky na reporting aj z iných dátových zdrojov ako napr: objekty, XML dokumenty.
Cieľom tejto práce je navrhnúť a vytvoriť nástroje na modelovanie a generovanie výstupných zostáv. Zhodnotiť vhodnosť použitia UML, XML Schéma, XML, XMI technológií pri modelovaní a generovaní zostavy. Na vybranom príklade ilustrovať proces modelovania a použitie vytvorených nástrojov.
V kapitole 2.Dostupnosť hotových riešení predstavíme niektoré dostupné riešenia na trhu a poukážeme na niektoré ich vlastnosti zaujímavé hlavne z pohľadu tejto práce a nášho riešenia.
Ako sme už spomínali typickým dátovým zdrojom pri tvorbe reportov sú relačné databázy. V kapitole 3.Dátové modelovanie a dátové zdroje sa zameráme práve na ne a na použitie CASE systémov a tradičné postupy pri dátovom modelovaní. Pôvodne sme chceli využiť CASE systémy, konkrétne CASE Rational Rose a jazyk UML pri tvorbe nášho riešenia. Prijatím konceptu XML ako všeobecného dátového zdroja však stratilo nasadenie CASE systémov a jazyka UML pri tvorbe nášho riešena zmysel. Keďže však CASE systémy zostanú aj naďalej nástrojmi na modelovanie objektových a dátových modelov, ukážeme v tejto kapitole, na základe XMI formátu, možnosť mapovania dokumentačných informácií týchto modelov, do nami používanej XML Schémy pre popis XML ako dátového zdroja.V kapitole 5.XMLSchéma ako rozhranie ukážeme zaujímavé riešenie Davida Carlsona, ktorý používa jazyk UML a CASE systémy na modelovanie samotnej XML Schémy.
Kapitola 4.XML, XMLSchéma a XSL je ľahkým úvodom do technológií XML, XMLSchéma a XSL, ktoré v našom riešení používame. Vysvetlíme základné princípy týchto technológií, ktoré sú nevyhnutné pre správne pochopenie tejto práce.
V kapitole 5.XMLSchéma ako rozhranie ukážeme dôvody, vedúce k použitiu XML Schémy ako rozhrania, ktoré delí proces prípravy reportu na dve časti, na prácu dátového špecialistu a na prácu tvorcu zostavy. Poukážeme na niektoré výhody takéhoto rozhrania a spomenieme možnosti prezerania a tvorby XMLSchém.
V kapitole 6.Proces modelovania, generovania a spúšťania reportu predstavíme celý proces od modelovania až po spúšťanie výstupnej zostavy, vysvetlíme v nej čo je vstupom a výstupom jednotlivých fáz modelovania, generovania a spúšťania reportu a aké výhody takáto koncepcia prináša.
V kapitole 7.Report Designer predstavíme vytvorený nástroj pre modelovanie a generovanie výstupných zostáv nazvaný Report Designer, popíšeme hlavné črty , možnosti a výhody tohto nástroja. Report Designer je web aplikácia, ktorá môže byť jednoducho začlenená do podnikového systému, intranetu. Klientská časť aplikácie je naprogramovaná v Microsoft Internet Exploreri a je postavená na technológiach HTML, CSS, JavaScript, DHTML, HTC, XML, XSL. Umožňuje jednoducho vizuálne a v známom prostredí (web prehliadača) modelovať, generovať a spúšťať výstupné zostavy. Voľbou prehliadača internetu ako cieľovej klientskej platformy sa odbúravajú náklady na inštaláciu a údržbu systému, nakoľko prehliadač má nainštalovaný, alebo zvládne jeho inštaláciu, aj bežný používateľ. Používateľ (tvorca reportu) naviac získava možnosť práce s Report Designerom po prihlásení sa na server, aj kdekoľvek vo svete prostredníctvom internetu, nie je tak viazaný na konkrétne pracovisko, môže tak flexibilne reagovať na dodatočné požiadavky na report aj mimo podniku.
V kapitole 8.Generovanie a spúšťanie zostavy na jednoduchom príklade demonštrujeme proces generovania a spúšťania repotu. Načrtneme spôsob generovania pri riešení niekoľkých čiastkových úloh. Kapitola 9.Systémové požiadavky obsahuje zoznam požiadaviek na serverovskú aj na klientskú časť aplikácie.
Z dostupných riešení na trhu spomenieme dva Crystal Reports od Seagate a JReport od spoločnosti Jinfonet software. Obidva produkty umožňujú tvorbu reportov, počnúc špecifikovaním dátového zdroja cez získavanie (dolovanie) požadovaných dát z dátového zdroja a ich úpravu (napr:zoskupovanie, súčtovanie), až po výsledné formátovanie výstupnej zostavy. Typickým zdrojom dát, s ktorým tieto nástroje pracujú je relačná databáza, kde získavanie dát prebieha formou príkazov v štandardnom jazyku relačných databáz SQL. Užívateľ týchto produktov musí byť znalý databázovej problematiky (ako sú uložené dáta, v akých tabuľkách a ako ich z nich získať) ako aj samotných požiadaviek na zostavy, a teda musí často poznať detaily z tej oblasti, ktorej sa report dotýka (napr:daňové priznania). V tejto práci ukážeme, že sa priam núka takéto prirodzené delenie procesu prípravy reportu:
- práca dátového špecialistu
- práca tvorcu zostavy (používateľa).
Spomenieme ešte niektoré ďalšie črty týchto produktov, ktoré budú z nášho pohľadu zaujímavé:
Crystal Report verzia 8.5 a JReport verzia 4.0 už umožňujú narábať s XML dátami ako so zdrojom dát. Avšak XML dokument musí reprezentovať dáta akoby jednej tabuľky z relačnej databázy. Nemôžeme teda využiť bohaté možnosti jazyka XML na zachytenie ľubovoľných dátových štruktúr. Takýto plochý "tabuľkový" pohľad týchto nástrojov je zrejmý, pretože oba produkty v konečnom dôsledku pracujú (pomocou špeciálneho drivera) s XML dátami ako s tabuľkou z databázy, a tak celá ďalšia filozofia práce ostáva nezmenená. Crystal Report dokonca umožňuje pristupovať k XML dátam z viacerých XML dokumentov, ktoré umožňuje viazať ako tabuľky v SQL pomocou joinov. V nástroji spoločnosti Seagate, ktorá má so svojím nástrojom Crystal Report vedúce postavenie v oblasti reportingu, badať od verzie 8.0 veľkú podporu nových web štandardov. Či už je to spomínaná práca s XML ako dátovým zdrojom, ale aj ako jednou z možností výstupu a XML ako transportný formát, alebo podpora web prehliadačov ako prehliadačov reportov (kým do verzie 8.0 to boli ich vlastné klientské prehliadače ).
Crystal Report verzia 8.5 a JReport verzia 4.0 už umožňujú narábať s XML dátami ako so zdrojom dát. Avšak XML dokument musí reprezentovať dáta akoby jednej tabuľky z relačnej databázy. Nemôžeme teda využiť bohaté možnosti jazyka XML na zachytenie ľubovoľných dátových štruktúr. Takýto plochý "tabuľkový" pohľad týchto nástrojov je zrejmý, pretože oba produkty v konečnom dôsledku pracujú (pomocou špeciálneho drivera) s XML dátami ako s tabuľkou z databázy, a tak celá ďalšia filozofia práce ostáva nezmenená. Crystal Report dokonca umožňuje pristupovať k XML dátam z viacerých XML dokumentov, ktoré umožňuje viazať ako tabuľky v SQL pomocou joinov. V nástroji spoločnosti Seagate, ktorá má so svojím nástrojom Crystal Report vedúce postavenie v oblasti reportingu, badať od verzie 8.0 veľkú podporu nových web štandardov. Či už je to spomínaná práca s XML ako dátovým zdrojom, ale aj ako jednou z možností výstupu a XML ako transportný formát, alebo podpora web prehliadačov ako prehliadačov reportov (kým do verzie 8.0 to boli ich vlastné klientské prehliadače ).
Ako sme už spomínali typickým dátovým zdrojom pre modelovanie reportov sú relačné databázy. Preto sme sa zamýšľali aj nad tým, ako využiť CASE systémy pri tvorbe reportov.
CASE systémy umožňujú modelovanie informačných systémov, počnúc od zachytenia používateľských požiadaviek formou use case, cez modelovanie objektov, modelovanie stavových a sequence diagramov, dátové modelovanie až po generovanie zdrojového kódu do rôznych programovacích jazykov, či skriptov pre vytvorenie relačnej databázy. Dôležitou vlastnosťou týchto nástrojov je aj tzv. Reverse Engineering, ktorý umožňuje spätné rozpoznanie modifikovaných zdrojových kódov programu a zanesie zmeny aj do modelu v CASE systéme. CASE systémy sú založené na jazyku UML. Samotný jazyk len popisuje objekty modelovania, preto vznikli CASE systémy, ktoré umožňujú vizuálne používať tento jazyk pomocou rôznych grafických elementov a diagramov. Samozrejme v týchto nástrojoch je priestor pre bohatú dokumentáciu každej modelovanej položky. Tieto systémy na zachytenie návrhu aplikácie, pre svoje schopnosti kompexného návrhu, sú v súčasnosti nasadzované pri návrhu každého väčšieho projektu, databázy či objektového systému. Preto sme ich pôvodne chceli použiť aj v našej aplikácii a vytvoriť nástroj, ktorý by s pomocou CASE systémov a informácií v nich namodelovaných, umožňoval jednoduchým spôsobom modelovanie reportov. Neskôr sme sa však rozhodli pre zmenu metodiky tvorby reportov, dôvody rozoberáme v kapitole 5.XMLSchéma ako rozhranie. V súčasnosti sa ukazuje potreba tvorby výstupných zostáv nie len z tradičných dátových zdrojov (databáza) ale aj zo zdrojov ako napríklad objekty nejakej aplikácie či XML dokumenty. V tejto práci sme chceli ponúknuť nástroj aj pre tieto nové typy dátových zdrojov, preto sme začali uvažovať o XML dokumentoch ako o všeobecných dátových zdrojoch. Prijatím tohto konceptu konceptu však stratilo nasadenie CASE systémov a jazyka UML pri tvorbe nášho riešena zmysel, pretože CASE systémy neumožňujú modelovať XML Schému, popisujúci formát, k našim XML dátovým zdrojom. Aj tu sa však objavujú prvé návrhy, ako podchytiť návrh XML aplikácií, bližšie o riešení Davida Carlsona uvedieme v kapitole 5.XMLSchéma ako rozhranie.
Uvedomujeme si však, že za väčšinou XML dátových zdrojov budú dáta uložené v databáze (zachytenej obyčajne v CASE systéme) a dátový špecialista bude musieť vytvoriť XML Schému na základe požiadaviek tvorcu zostavy a poskytnúť tieto dáta vo forme XML vyhovujúcej vytvorenej XML Schéme. Je možné navrhnúť riešenie, ako sprístupniť informácie z CASE systému pre potreby modelovania a dokumentovania vytváranej XMLSchémy. Väčšina CASE systémov umožňuje export modelov vo formáte XMI - XML Metadata Interchange , dokonca niektoré pracujú s ním ako s natívnym formátom, napríklad volne šíriteľný nástroj Together. Hlavným cieľom návrhu formátu XMI bolo umožniť jednoduchým spôsobom výmenu metadát medzi rôznymi modelovacími nástrojmi založenými na UML. XMI je na formáte XML, čo uľahčuje jeho nasadenie aj využitie. V tomto formáte vieme získať z CASE systémov, kompletné informácie o namodelovaných projektoch, vrátane dokumentačných častí. Na obrázku nižšie vidíme jednoduchý objektový model v CASE Rational Rose, ktorý obsahuje iba jednu tiredu osoba. Všimnime si dokumentáciu k tejto triede.
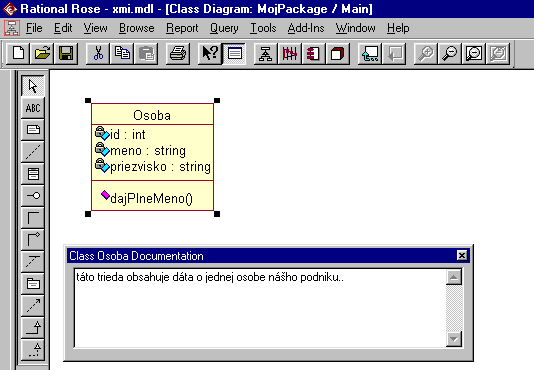
1.Ukážka CASE Rational Rose

2.Ukážka XMI formátu
1.Ukážka CASE Rational Rose
2.Ukážka XMI formátu
XML (Extensible Markup Language) je univerzálny formát pre štruktúrované dokumenty a dáta na webe. Toľko hneď prvá veta na webe W3 konzorcia [ 2 ], ktoré je normotvorcom tohto formátu, v sekcii venovanej XML. Slovo markup hovorí, že sa ide o značkovací jazyk. Značkovacím jazykom je aj dobre známe HTML. Tak ako v HTML, aj v XML tvoríme dokument pomocou značiek (tagov). Pod značkou chápeme zápis
<meno_značky/>
takúto značku nazývame nepárová alebo zápis
<meno_značky
meno_attribútu="hodnota atribútu">
telo značky
</meno_značky>
pre párovú značku, kde hodnota atribútu musí byť ohraničená úvodzovkami alebo apostrofmi a telo značky obsahuje text alebo ľubovoľný ďalší počet značiek. Na rozdiel od HTML, kde prehliadač kódu "porozumie" aj keď párové značky nie sú pouzatvárané, prípadne sú značky prekrížené, v XML musíme tieto pravidlá striktne dodržiavať, inak to má za následok chybu pri parsovaní XML dokumentu. Tieto požiadavky nie sú samoúčelné, ale umožňujú rýchlo analyzovať (parsovať) syntax dokumentu pomocou parserov. [ 1 ]
3.Ukážka XML dokumentu
Značka <chapter header="XML, XMLSchéma a XSL">... obsahuje celú kapitolu s nadpisom XML, XMLSchéma a XSL. Tá obsahuje niekoľko párových značiek <para>...</para>(reprezentujú odstavce), ktoré môžu obsahovať značky <ref/>,<code/>,<img/> reprezentujúce referenciu, zdrojový kód a značku pre obrázok. Na hlavnej úrovni (deti značky root) si môžeme všimnúť ešte ďalšiu značku <resources/>, ktorá obsahuje značkovanie popisujúce zdroje tejto práce. Všimnime si, že značky nám prirodzene tvoria akýsi strom. Toto značkovanie, zatiaľ nie je nijako obmedzené a značky môžeme ľubovoľne vnárať a používať. Jediné obmedzenie, ktoré nám kladie XML je, že musíme mať iba jeden koreň (prvá značka v strome).
Z dôvodov rozoberaných nižšie sa zavádza definícia značkovania DTD alebo XML Schéma, ktorá kladie obmedzenia na používanie značiek. DTD (Data Type Definition) je predchodca XML Schémy, ktorého syntax bola nevyhovujúca, prevzaná ešte z jazyka SGML.

4.Ukážka XML Schémy
Všimnime si, že v XML Schéme na obrázku začínajú všetky značky (tagy) prefixom "xs". XML umožňuje zavádzať tzv. namespaces. Každá značka v XML dokumente patrí nejakému namespace, ktorý musí byť definovaný ešte pred prvým výskytom, dvojicou prefix a identifikátorom, ktoré tento namespace popisuje. Tagy, ktoré sú bez prefixu, patria do defaultného namespace. Teda v XML dokumente môžem používať viacero rôznych značkovaní, ktoré sa líšia práve v namespace. Môžeme vytvoriť XML dokument, kde použijeme rovnakú značku <stock/>, len s iným prefixom. Napr:
<company:stock><my:stock/></company:stock>
Tiež môžeme pri jednom elemente (značke) použiť atribúty z rôznych značkovaní (namespaces).
<my:item my:id="001" company:id="00023"/>
Môžeme teda jednoducho používať už existujúce značkovania napr:HTML vo svojom formáte.
XSL (Extensible Stylesheet Language) je jazyk, ktorý umožňuje zápis pravidiel transformácie XML Dokumentu na iný XML alebo non XML dokument. Najčastejšie sa používa na zápis štýlov, pomocou ktorých prezentujeme XML Dokument na výstupných zariadeniach ako tlačiareň, HTML prehliadač, PDA zariadenie atď.
Oproti CSS kaskádovým štýlom má oveľa bohatšie výrazové prostriedky. XSL štýl pozostáva zo šablón.
<xsl:template match="výraz">
telo šablóny
</xsl:template>
Tie určujú ako sa značky z XML dokumentu majú transformovať. výraz špecifikuje pomocou XPATH štandardu [ 2 ], na akú značku môže XSL procesor aplikovať danú šablónu. Do tela šablóny môžeme zapísať rôzne značkovanie, ktoré chceme mať na výstupe.

5.Ukážka XSL štýlu
Na obrázku vidíme XSL štýl, pomocou ktorého zobrazíme obsah tejto práce, z XML dokumentu, ktorý je popisovaný vyššie. (obr. 3 ) Všimnime si, že v XSL dokumente je opäť značkovanie založené na XML. Značky, ktorým rozumie XSL procesor majú prefix "xsl". Hneď za hlavičkou súboru je šablóna <xsl:template match="/">, ktorá sa vykoná ako prvá v každom XSL dokumente ak je uvedená, pretože XSL Procesor prechádza stromom XML dát a vyhľadáva vhodné šablóny na transformáciu a backslash značí prvú značku v XML strome, v našom prípade to je značka <root>. Táto šablóna nám vyrobí hlavičku HTML súboru, naimportuje kaskádové štýly CSS a iniciuje vykonanie šablóny pomenovanej "toc" - table of content. Šablóna toc vytvorí jeden span s id rovné "toc" a pre všetky značky <chapter> vytvorí príkazom <xsl:for-each select="//chapter">... span ktorý obsahuje číslo kapitoly, HTML linku na danú kapitolu a príkazom <xsl:value-of select="@header"/> aj prislúchajúci nadpis kapitoly.

6.Výsledok transformácie - HTML dokument

7.Výsledok transformácie v prehliadači
Nakoniec si ešte uvedomme, že XSL môžeme použiť nie len ako štýl, ktorý určuje vzhľad dokumentu ale môžeme ho aj využiť na transformáciu z jedného jazyka (značkovania) do druhého jazyka, čo aj v tejto práci využívame. Dá sa tak riešiť napríklad aj konverzia formátov medzi rôznymi verziami spravovaných dokumentov.
Ak začneme rozmýšľať o rôznych dátových zdrojoch pre reporting ako sú relačné databázy, XML dáta alebo dáta poskytované priamo objektami, vzniká otázka, ako k týmto dátam pristupovať cez jednotné rozhranie, ktoré by odclonilo rôznosť týchto zdrojov. Napr: Crystal Report pristupuje k XML ako k dátovému zdroju pomocou špeciálneho drivera, ktorý rozumie požiadavkám v SQL a sprístupňuje tvorcovi zostavy XML ako nejakú databázovú tabuľku, prípadne skupinu tabuliek. V tomto prípade by sme mohli brať za akési rozhranie samotný jazyk SQL. Nemyslíme si však, že takýto relačný - databázový pohľad na dáta bude vždy vyhovovať. Napríklad uvažujme o objektoch nejakej aplikácie ako o dátových zdrojoch, v takom prípade mapovať dáta do relačných tabuliek nevyzerá byť dobrou voľbou. Intuitívne cítime, že komplikovanejšie dátové štruktúry viac vystihuje bohatšie (nie "tabuľkové") XML. Navyše XML nám umožňuje svojím značkovaním viac udržať, ak je to potrebné, logickú štruktúru dát a je oveľa viac čitateľné pre laika (používateľa) ako nejaký dátový model relačnej databázy. Nie je problémom ani mapovať relačnú databázu do XML, aj keď nemyslíme si že to bude treba, a pomocou XML Schémy kontrolovať aj obmedzenia a referenčnú integritu. Z týchto dôvodov začíname uvažovať o XML ako o všeobecnom dátovom zdroji. Keďže XML Schéma nám umožňuje "typovať" XML dokument a kontrolovať správnosť XML dokumentu voči nejakému značkovaniu (štruktúre), vhodným rozhraním sa ukazuje XML Schéma.
Niektoré výhody XML Schémy ako rozhrania:
- XML formát
- možnosť špecifikovať typ dátových položiek ako napr:string
- možnosť jednoduchého validovania dát
- výrazovo bohatý jazyk, možnosť zachytiť ľubovoľnú dátovú štruktúru
- dokumentačný jazyk, obsahuje možnosť dokumentovať každú dátovú položku
Ako sme už skôr uviedli, zdá sa nám prirodzená deľba procesu prípravy reportu takáto:
- práca dátového špecialistu
- práca tvorcu zostavy (používateľa).
Riešení je viacero. Spomeniem aspoň nasledujúce riešenie Ralfa Schweigera PhD dostupné na adrese http://www.xsbrowser.com.
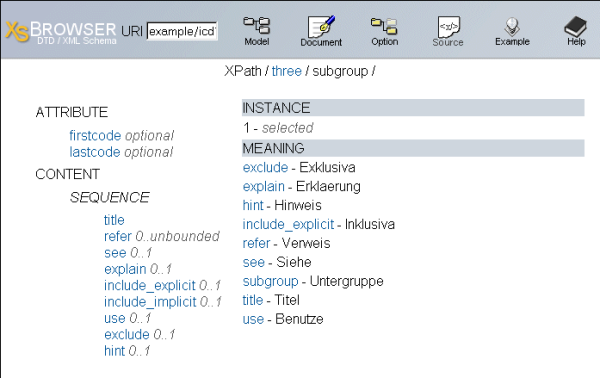
8.XSBrowser
8.XSBrowser
Pre potreby tvorcu zostavy v našej aplikácii, tiež použijeme podobné riešenie s našou vlastnou funkčnosťou, ktoré však využije vstavaný XML parser prehliadača Microsoft Internet Explorer v6.0. Naše riešenie zobrazí XML Schému ako strom dostupných elementov, ich atribútov a bude rozšírené o možnosť aktívne pracovať s XML Schémou v procese modelovania zostavy (drag and drop dátových položiek).
Ďalej nás bude iste zaujímať ako modelovať XMLSchému, aj tu sa núka hneď niekoľko riešení. Jedným z momentálne najlepších editorov, podporujúcich modelovanie XMLSchémy, je známy XMLSpy, ktorý vidíme na obrázku nižšie. Umožňuje modelovať, validovať XMLSchému podľa poslednej verzie štandardu. Jednou zo zaujímavých vlastností je generovanie XMLSchémy podľa dodaného XML dokumentu. Samozrejme takto generovaná XML Schéma nie je vždy postačujúca ale návrh XMLSchémy sa takto značne zrýchli a uľahčí.
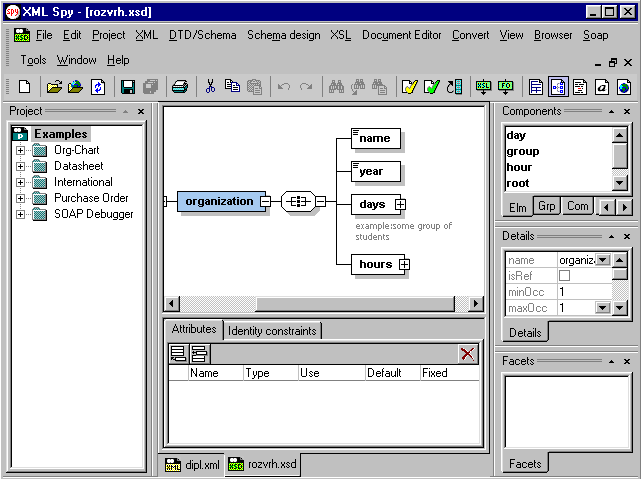
9.XMLSpy
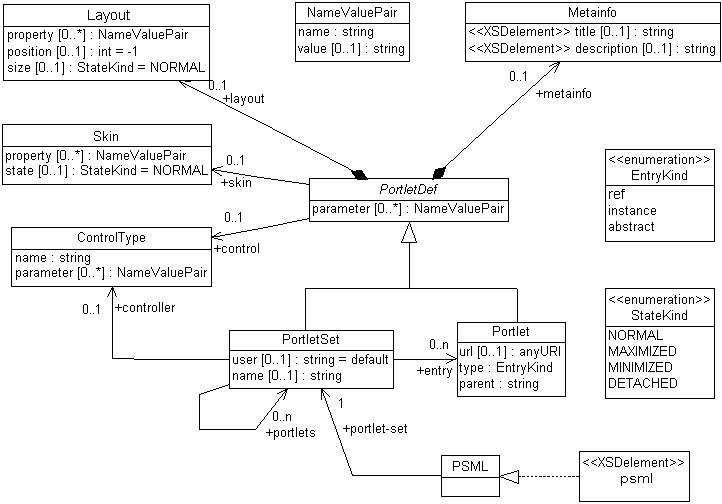
10.UML model predstavujúci XMLSchému k PSML
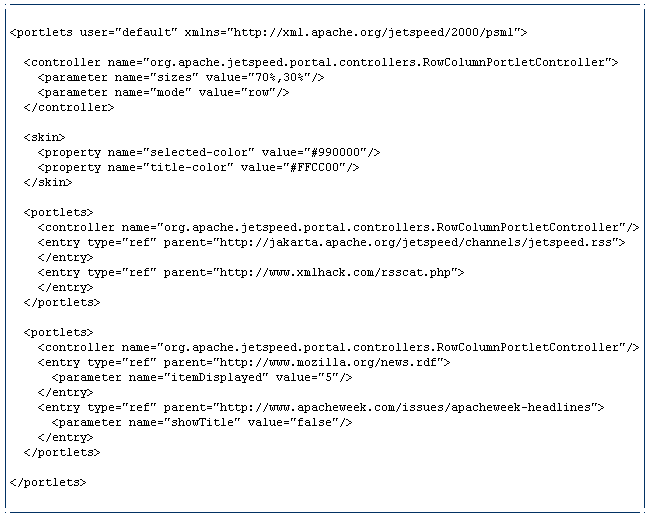
11.Ukážka PSML
9.XMLSpy
10.UML model predstavujúci XMLSchému k PSML
11.Ukážka PSML
V predošlej kapitole sme sa zaoberali XML Schémou ako rozhraním, ktoré delí proces prípravy reportu na dve časti: prípravu dát a prípravu prezentácie dát. Proces prípravy dát závisí najmä od typu použitého dátového zdroja, preto sa nedá jednoducho zovšeobecniť. Každý dátový zdroj má svoje špecifiká a je potrebné zohľadniť rôzne prístupy. Ak sa jedná o databázu, najčastejším spôsobom získavania dát bude použitie klasických reportovacích nástrojov, napríklad už spomínaný Crystal Report. Nesmieme však zabúdať na to, že databáza je často iba skladom dát a potrebné dátové vzťahy sú dodané až objektami nejakej aplikácie. V takom prípade je potrebné exportovať dáta priamo z objektov danej aplikácie. Aj pri XML ako dátovom zdroji je niekedy potrebné dáta transformovať na XML dáta vhodné pre reporting, či už zahrnutím ďalších externých zdrojov alebo zjednodušením zložitej štruktúry, či poskytnutím iného pohľadu na tie isté dáta. Napríklad môžeme mať XML, ktoré popisuje študentov a ich vyučujúcich a požiadavku na dva rôzne reporty. Jeden bude prehľadom vyučujúcich a počtu študentov, ktorých učia. Druhý prehľadom študentov a vyučujúcich, ktorí ich učia. Vidíme, že v prvom prípade by nám vyhovovali XML dáta zoskupené najprv podľa vyučujúcich, v druhom prípade naopak najprv podľa študentov.
Ak sa uchýlime k XML ako všeobecnému dátovému zdroju a k XML Schéme, ktorá ho popisuje, ako k rozhraniu môžeme pracovať na spoločnom riešení druhej časti tvorby reportu: prípravy prezentácie dát. V tejto práci sa preto ďalej zameráme na druhú časť, teda prácu tvorcu reportu. Na obrázku máme zachytený proces prípravy prezentácie reportu. Je rozčlenený na tri fázy
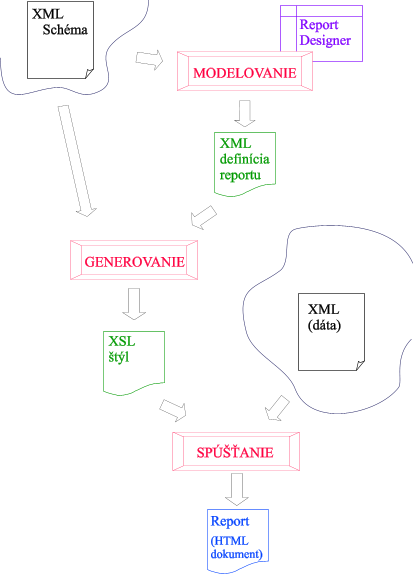
12.Proces modelovania, generovania a spúšťania reportu
Modelovanie - Report Designer- modelovanie
- generovanie
- spúšťanie zostavy (reportu)
12.Proces modelovania, generovania a spúšťania reportu
V tejto fáze tvorca reportu navrhuje vzhľad výstupnej zostavy, rozmiestňuje dátové polia, volí formátovanie, nastavuje štýly a podobne. Pre túto fázu máme napísanú aplikáciu Report Designer. Je to vizuálny nástroj, ktorý umožňuje modelovať výstupné zostavy, bližšie sa naň z hľadiska funkčnosti i implementácie pozrieme v ďalšej kapitole. Teraz je potrebné si uvedomiť, že vstupom do Report Designéra je XML Schéma, ktorá popisuje XML dáta, z ktorých chceme vyrobiť report. Výstupom je interná definícia reportu v XML formáte.
Generovanie
Pre generovanie je opäť potrebná XML Schéma a namodelovaná zostava zachytená v XML definícii reportu. Výsledkom tejto fázy je XSL štýl, ktorým možno požadované dáta prezentovať v namodelovanom tvare. Výsledkom následnej transfomácie pri spúšťaní reportu je HTML dokument, ale pri takto zvolenom koncepte generovania a modelovania je možné jednoducho vytvoriť a použiť generátory XSL štýlov, ktoré transformujú aj do iných používaných formátov napr:PDF,RTF a podobne. Táto fáza prebieha na strane servera, používateľ už do nej aktívne nevstupuje. Viac o tejto fáze uvedieme v kapitole 8.Generovanie a spúšťanie zostavy.
Spúšťanie reportu
V poslednej fáze spájame vygenerovaný XSL štýl s XML dátami. Transformácia prebieha obyčajne na strane servera klient dostáva odpoveď - report vo forme HTML dokumentu, ktorý je výsledkom transformácie. Iniciátorom tejto fázy je obyčajne koncový uživateľ, ktorý si volí požadovaný report z repozitára reportov a špecifikuje prípadné parametre vyplnením nejakého HTML formulára. Spustiť report ale môže aj nejaký proces, ktorý zaregistruje výtlačok (výsledok) reportu do nejakého repozitára a podobne.
Cieľom tejto práce je navrhnúť a implementovať nástroje na modelovanie a generovanie výstupných zostáv a na vybranom príklade ilustrovať ich použitie. V tejto kapitole predstavíme vizuálny nástroj pre tvorbu reportov nazvaný Report Designer, popíšeme hlavné črty, možnosti a výhody tohto nástroja. Zmienime sa aj o niektorých zaujímavých implementačných problémoch a na jednoduchom príklade rozvrhu ukážeme jeho použitie.
Report Designer je web aplikácia. Podrobnejšie sa o architektúre a systémových požiadavkách zmienime v kapitole 9.Systémové požiadavky, teraz len krátko. Na serveri je repozitár namodelovaných reportov a dostupných XML dátových zdrojov a ich XML Schém. Používateľ môže na vyžiadanie upravovať namodelované zostavy, vytvárať nové zostavy a dopĺňať dátové zdroje, poskytnutím XML Schémy a ďalších potrebných informácií. Celá aplikácia môže byť jednoducho začlenená do nejakého podnikového systému, intranetu, odkiaľ je možné prevziať aj autorizačné informácie, a tak podmieniť prístup k jednotlivým funkciám, či reportom a dátovým zdrojom. Na klientskej strane je potrebný HTML prehliadač, ktorý podporuje nové web technológie, čo je značnou výhodou, pretože nie je nutné inštalovať špeciálneho klienta a navyše keďže je to web aplikácia je toto riešenie dostupné kdekoľvek z internetu. Terajšie riešenie je postavené na prehliadači firmy Microsoft Internet Explorer 6.0 a technológiách HTML, CSS, JavaScript, DHTML, HTC, XML, XSL. [ 2 ] [ 3 ]
HTML komponenty
Zastavme sa pri technológii HTC - HTML komponentoch, ktoré boli použité pri programovaní klienta. HTML komponenty rozširujú zaujímavým smerom prácu s DOM - dokument object model a DHTML, umožňujú rozšíriť sadu povolených značiek v HTML a prisúdiť im vlastné chovanie. Môžeme tak zapuzdriť požadovanú funkčnosť, a takýto komponent veľmi jednoduchým spôsobom opätovne využívať. Na obrázku je príklad komponentu kontextového menu. Všimnime si ako jednoducho môžeme toto menu vytvoriť.

13.Ukážka HTML komponenty - kontextové menu

14.Ukážka zdrojového kódu - popup.htc
XMLSchéma Viewer13.Ukážka HTML komponenty - kontextové menu
<?IMPORT NAMESPACE="UI" IMPLEMENTATION="popup.htc">Stručný náčrt implementácie vidíme na ďalšom obrázku.
14.Ukážka zdrojového kódu - popup.htc
<UI:POPUP_MENU atribút="hodnota property">...METHOD metódy nášho komponentu - značky, ktoré môžeme vyvolať z JavaScriptu dokonca ATTACH, EVENT môžeme zachytávať a vytvárať udalosti. (napr: pohyb myšou je udalosť). Náš komponent môže obsahovať akoby vlastnú HTML stránku, ktorá sa zahrnie do hlavnej stránky. Používaním týchto HTML komponentov je kód prehľadnejší, riešia sa možné konflikty v JavaScripte a máme možnosť efektívne znovu využívať naprogramovaný kód. [ 3 ]
Skôr ako popíšeme XML Schéma Viewer, pozrime sa na nasledujúce obrázky. Tie zobrazujú jednoduché XML dáta k rozvrhu a príslušnú XML Schému. Z týchto dát neskôr vyrobíme report - rozvrh hodín. Ak neuvedieme inak, v prípade, že budeme písať o XML dátach a XML Schéme, tak budeme myslieť tieto dokumenty.

15.XML dáta - rozvrh

16.XML Schéma - rozvrh
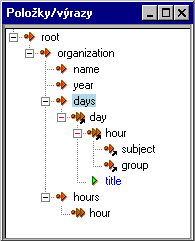
17.Prehliadač XML Schém
Modelovanie HTML Tabuľky a umiestňovanie dátových polí15.XML dáta - rozvrh
16.XML Schéma - rozvrh
17.Prehliadač XML Schém
Ďalším základným komponentom Report Designera je Modeler tabuľky (MT), ktorý umožňuje vizuálne modelovať HTML tabuľku, pridávať, odoberať stĺpce, riadky, vnorené tabuľky, vymieňať bunky, ich obsah, presúvať celé riadky, spájať, rozdeľovať bunky. Keďže reporty sú zväčša tabuľkovo orientované, pre tvorcu reportu je HTML tabuľka základným stavebným prvkom. MT poskytuje sadu metód, ktorými možno pristupovať k elementom tabuľky, tak možno nastaviť CSS štýly a atribúty. Ale nie len to, MT umožňuje vložiť nejaké HTC komponenty a priamo ich vkladať do buniek tabuľky. Tak možno vložiť do tabuľky aj textové elementy, alebo tzv. dátové polia, to je obsah elementov alebo atribútov nášho XML dokumentu. Tie môžeme vkladať do tabuľky drag and drop priamo z XSV.

18.Panel nástrojov pre tabuľku

19.Nastavenie štýlu pre element
Iterácie18.Panel nástrojov pre tabuľku
19.Nastavenie štýlu pre element
Nebol by to report, ak by sa tam niečo neopakovalo. Ako sme už spomenuli, iterovateľné dátové polia sú v XSV označené zdvojenou hnedou ikonou. To však nestačí pre vygenerovanie XSL šablóny potrebujeme mať informáciu, ktoré namodelované elementy patria k danej iterácii, resp. ktoré namodelované elementy a ich obsah majú iterovať spolu s dátami. Na obrázku vidíme, že priradiť element tabuľky nejakej iteráci,i môžeme veľmi jednoducho pomocou kontextového menu. Na každý element v tabuľke vieme takto nastaviť jej príslušnosť jednej alebo viacerým iteráciám.
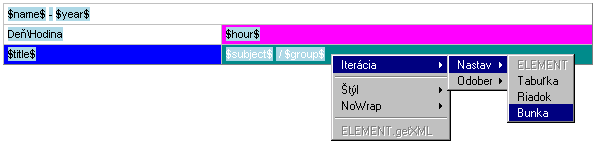
20.Nastavenie iterácie na element
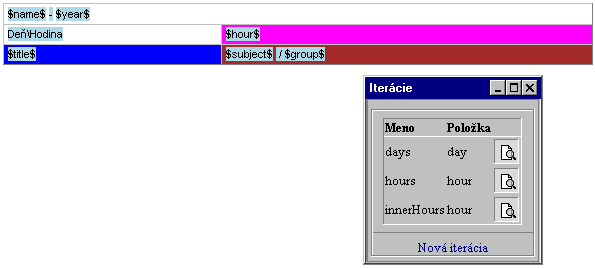
21.Modelovanie iterácií
Vlastnosti20.Nastavenie iterácie na element
21.Modelovanie iterácií
<day title="pondelok">
<hour title="8.00"/>
<hour title="9.00"/>
...
</day>
vnorené v značke <day/>. Vo výstupnej zostave sa pre každú značku <hour/> vytvorí jedna bunka tabuľky s príslušným obsahom. Posledná iterácia nám slúži na zobrazenie hodín v predchádzajúcom riadku pre každý stĺpec tabuľky, v ktorom sa nachádzajú rozvrhované akcie. Z toho plynie, že druhá iterácia by mala mať najviac taký počet značiek v XML dátach ako posledná.
Ako sme už spomínali, namodelovaná zostava sa ukladá do interného XML formátu, ktorý sa použije pri generovaní výstupnej zostavy. Keďže ide o XML dokument, samozrejme je k nemu aj XML Schéma, ktorá je k dispozícii v dvoch súboroch tw.xsd a base.xsd v prílohe tejto práce. Ako ukážeme, práve s týmito súbormi pracuje Report Designer pri nastavovaní vlastností elementov tabuľky a ukladaní zostavy. Táto XML Schéma sa teda využíva nie len na kontrolu a validáciu (prípadne verziovanie), či daný XML dokument je skutočne správne namodelovanou výstupnou zostavou, ale slúži aj pre vnútornú potrebu Report Designera. Komponent na ďalšom obrázku nám umožňuje nastavovať vlastnosti jednotlivých elementov tabuľky na základe spomínaných schém, povolí nastaviť len tie atribúty, ktoré XMLSchéma skutočne obsahuje. Takto môžeme jednoducho rozširovať možnosti nastavovania atribútov elementov v Report Designer tým, že tieto atribúty doplníme do XML Schémy.
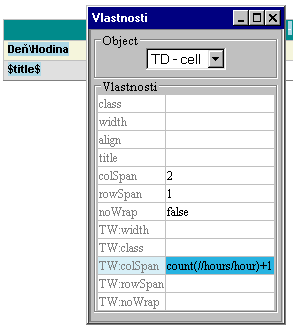
22.Nastavenie vlastností
Uloženie zostavy v internom formáte 22.Nastavenie vlastností
Aby sme mohli s namodelovanou zostavou ďalej jednoducho pracovať, zvolili sme si na jej uloženie XML formát, ktorého ukážku vidíme na obrázku. Všimnime si, že obsahuje dve značky na hlavnej úrovni <LAYOUT>, tá nesie informácie o vzhľade zostavy a <ITERATIONS> obsahuje informácie o namodelovaných iteráciach. Obsah značky <ITERATIONS> si rozoberieme v ďalšej kapitole 8.Generovanie a spúšťanie zostavy, kde aj ukážeme jej použitie v procese generovania. Teraz si bližšie všimnime značku <LAYOUT>, tá obsahuje HTML definíciu tabuľky s nastavenými CSS štýlmi a atribútmi. Je obohatená o atribúty a elementy s prefixom TW. Atribúty s prefixom TW a ich význam sme už rozoberali vyššie a elementami môžu byť len <TW:DATAFIELD_ELEMENT> a <TW:TEXT_ELEMENT>. Prvý element predstavuje dátovú položku, ktorú sme umiestnili drag and drop z XSV do tabuľky a druhý predstavuje HTML formátovaný text. Uvedomme si ešte, že tieto elementy sú HTML komponenty vložené do MT a teda obsah značky <LAYOUT> môže browser jednoducho bez akejkoľvek ďalšej inicializácie zobrazovať. Pri ukladaní layoutu zostavy, tak ako aj pri komponente na prácu s atribútmi elementov, využívame XML Schému interného formátu zostavy. Ukladajú sa tak skutočne iba v XML Schéme povolené HTML atribúty a navyše naše špeciálne atribúty s prefixom TW.

23.Interný XML formát pre uloženie namodelovanej zostavy
23.Interný XML formát pre uloženie namodelovanej zostavy
Namodelovaná zostava je uložená v repozitári na serveri. Na požiadanie sa z danej zostavy a príslušnej XMLSchémy na strane servera vygeneruje XSL štýl. Generovanie je naprogramované v Jave a zapuzdrené v JSP. Využité sú aj JSP tag library pre prácu s XML dokumentom a pre XSL transformácie. Na XSL transformácie je použitý Xalan - XSLT stylesheet processors in Java a na prácu s XML s Xalanom dodaný XML parser. Oba vstupné dokumenty i výstupný XSL štýl sú v XML formáte, preto celé generovanie je práca s XML DOM. Na prácu s XML DOM v Jave je použitý štandardný balík org.w3c.dom.

24.Zachytenie iterácií

25.Vygenerovaný XSL štýl
24.Zachytenie iterácií
25.Vygenerovaný XSL štýl
NodeList attrs = XPathAPI.selectNodeList(data,"//@TW:*");
Node xnode, pnode;
String localName;
Attr attr;
for(int j=0; j<attrs.getLength(); j++){
xnode=attrs.item(j);
pnode = (Node) ((Attr) xnode).getOwnerElement();
localName = xnode.getLocalName();
attr = ((Element) pnode).getAttributeNode(localName);
attr.setValue("{" + xnode.getNodeValue() +"}");
((Element)pnode).removeAttributeNode(((Attr)xnode));
}
Predchádzajúci kód teda napríklad z pôvodného
<TD colSpan="2" TW:colSpan="="count(//hours/hour)+1)" ...
vytvorí
<TD colSpan="{count(//hours/hour)+1)}" ...
zložené zátvorky hovoria, že ide o XPATH výraz, ktorý sa bude interpretovať.
Na obrázku (obr. 24 ) si ešte všimnime elementy <TW:DATAFIELD_ELEMENT>, tie predstavujú dátové položky. Výber skutočných hodnôt z XML dát týchto dátových položiek v XSL štýle zabezpečí nasledujúci kód. V cykle si postupne pre všetky dátové položky dataFields pripravíme pomocný node xsl:value-of s namespace, ktorý hovorí, že ide o XSL príkaz. Metódou getPath(...) získame cestu k danému elementu v XML dátovom strome na základe XML Schémy a aktualného kontextu (iterácie). Nastavíme atribút select pomocneho node na hodnotu path a nahradíme ho za pôvodný element. Výsledkom teda bude napríklad <xsl:value-of select="root/organization/year" />.

26.Namodelovaná zostava

27.Výstupná zostava
String path;
Element pom;
Node tmpNode;
NodeList dataFields;
Node root=XPathAPI.selectSingleNode(data,"//ROOT");
dataFields=XPathAPI.selectNodeList(((Node) it), ".//TW:DATAFIELD_ELEMENT", root);
try{
//pretvorim TW:DF
for(int i=0; i<dataFields.getLength();i++){
tmpNode=dataFields.item(i);
pom=data.createElementNS("http://www.w3.org/1999/XSL/Transform", "xsl:value-of");
path=getPath(((Element) tmpNode).getAttribute("refId"), itPath, schema)
pom.setAttribute("select", path);
tmpNode.getParentNode().replaceChild(((Node)pom), tmpNode);
}
}catch(Exception e){
System.err.println(e);
}
Takýmto spôsobom je vygenerovaný celý XSL štýl na obrázku (obr. 25 ), ktorý sa potom použije na vytvorenie výstupnej zostavy. Ak si používateľ vyžiada spustenie zostavy, vyberie sa tento XSL štýl z repozitára spojí sa s príslušnými XML dátami a výsledok transformácie sa zašle ako odpoveď.
26.Namodelovaná zostava
27.Výstupná zostava
Celé riešenie je web aplikácia, preto požiadavky na prevádzku systému sú minimálne. Pre jednoduchú inštaláciu bol na klientskej strane kladený veľký dôraz na využitie možností internetového prehliadača bez ďalších rozšírení. Server je postavený na Open Source produktoch.
- Server
- Hardware:Pentium III 800MHz, 256MB RAM
- Software:
- Windows NT (Linux)
- JVM - Java virtual machine
- Tomcat 3.1.2 (HTTP Server + JSP a Servlets engine)
- Klient
- Hardware:Pentium 233MHz, 128MB RAM
- Software:
- pre modelovanie:
- Windows 98+
- Microsoft Internet Explorer 6.0
- pre spúšťanie výstupných zostáv:
- Windows, Linux, Mac, Unix
- MSIE, Netscape, Mozilla, Opera
- pre modelovanie:
V tejto práci sa nám podarilo dosiahnuť hlavný cieľ, vytvoriť nástroje na generovanie a modelovanie výstupných zostáv a navrhnúť metodiku tvorby reportov. Použitie týchto nástrojov sme demonštrovali na jednoduchom príklade. Veľkým prínosom pri tvorbe riešenia bolo použitie nových technológií ako XML, XML Schéma či XSL a rozhodnutie implementovať tieto nástroje ako web aplikáciu s využitím Internet Explorera ako klientskej platformy, čím odpadá nutnosť inštalácie špeciálneho klienta a umožňuje to vysokú dostupnosť nástrojov a nízke prevádzkové a zriaďovacie náklady tohto riešenia. Veľkou výhodou takéhoto riešenia je aj možnosť jednoduchého začlenenia tejto aplikácie do podnikových systémov, intranetov a dostupnosť z akéhokoľvek miesta prostredníctvom internetu po prihlásení sa na podnikový server. Takéto riešenie nám umožňuje rozmýšľať aj o ďalších rozšíreniach vytvorených nástrojov. Rozšírenie Report Designera o modelovanie podmienených sekcií, parametrizovanie zostáv, modelovanie XSL šabón a rekurzívne spracovanie dát, možnosť modelovania ďalších HTML elementov ako href, img atď. Naviac v dobe písania tejto práce boli W3C konzorciom publikované aj nové pracovné návrhy štandardov XSLT 2.0 a XPATH 2.0, dokonca sú dostupné aj prvé implementácie (XSLT procesor SAXON), čo dáva nádej na začlenenie nových zaujímavých vlastností aj pre naše riešenie. Ďalej je náš systém rozšíriteľný o možnosť generovania zostáv v ďalších výstupných formátoch ako PDF,RTF, alebo v jednoduchšom prípade napísaním iba transformačného XSL štýlu aj do iných. V práci sme poukázali aj na možnosť využitia CASE systémov, aj keď nie v pôvodne zamýšľanom rozsahu (kvôli zmene metodiky návrhu reportov), na modelovanie XMLSchémy a sprístupnenia dokumentačných informácií. Správnym sa ukázalo prijatie XML ako všeobecného dátového zdroja a XMLSchémy ako rozhrania medzi získavaním dát, dátovým modelovaním na jednej strane a modelovaním výstupnej zostavy na strane druhej. Teda členenie procesu prípravy reportu na prácu dátového špecialistu a prácu tvorcu reportu. Výrazne sa takýmto rozdelením rolí zvýši efektivita práce, nakoľko dátový špecialista je odbremenený od navrhovania zostavy, ktorej nerozumie a na druhej strane tvorca zostavy, ktorý je odborníkom na danú problematiku, ktorej sa report dotýka (napr: daňové priznania), nie je nútený zaoberať sa technikami získavania dát.